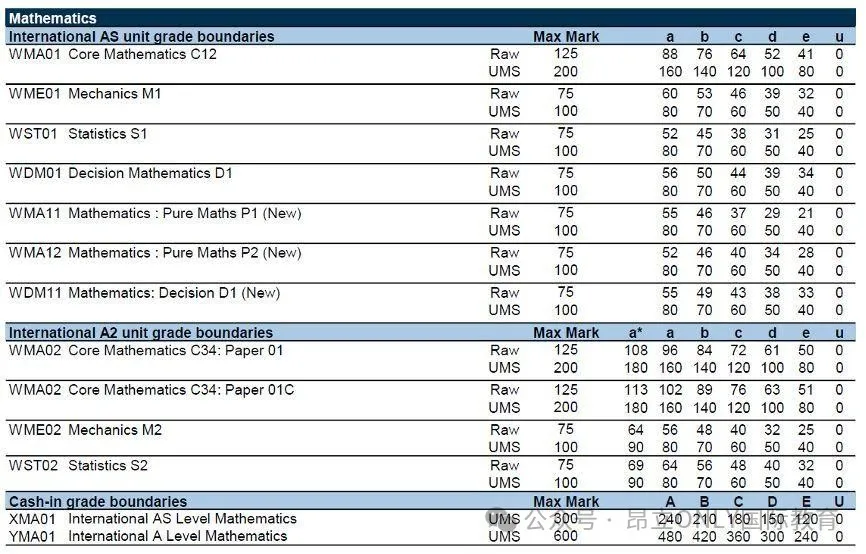
置信水平和置信区间是AP考试中每年必定会考查的考点,也是经常让同学们很头疼的问题。做题的时候,经常会碰到题目中给出95% confidence interval这样的表述,这里的confidence level 95%究竟是什么含义呢?比如下面的题目:

题目的答案是E,大家可以把自己的思考过程记下来,后面会给出解析。
我们先一起回顾“统计推断”的定义:统计推断是根据样本数据对总体进行推断的过程,回答类似“在职人士中有本科及以上学历的占多少百分比?”,“全国一年级小学生的平均身高是多少?”等问题。
这类问题的共同点是寻找用来描述总体的一个数字化测量(numerical measure),通常是总体比例或者总体均值,称为参数(parameter)。参数是总体中所有个体的一个联合测量值,在寻找参数的过程中,我们会面临以下两种情形。
第一种情形:如果我们能够找到总体中每一个测量值,就可以准确计算出参数的大小,无需采用估计的方法获得参数的取值范围。以下面的题目为例:

大家要特别关注题干中陈述的which included all of the American Presidents and all of the British Prime Ministers,这句话代表可以拿到总体中每个个体的取值,直接计算参数即可完成比较,不再需要搜集样本并用样本统计量估计参数的过程,答案选B。
第二种情形:现实中我们遇到的大多数问题,很难找到总体中每一个个体的取值,只能通过搜集样本的方式计算出样本统计量,进而用统计量的值去估计总体参数值。这里大家要有一个最基础的认识,虽然此类情形下总体参数值未知,但它仍是一个固定值(fixed value),只是因为我们无法找到总体中每个个体的取值,所以我们无法得知其具体大小。
参数估计是概率统计学中的核心问题,我们可以用点估计(point estimator)估计总体参数的样本统计量,但不能期望点估计量能给出总体参数的精确值,因此需要在点估计基础上加减边际误差(margin of error)来计算区间估计。
大家熟悉的参数置信区间(confidence interval)的形式是:点估计值(point estimator)±边际误差(margin of error),置信水平(confidence level)是不断重复抽样时,构建的多个区间中能捕捉到总体参数的概率(这里要重点理解95%置信水平是指“构建多个区间中,包含总体参数值的区间个数占比为95%”)。
接下来,为大家梳理一下做置信水平和置信区间问题的判别标准。
第一,参数的置信区间为:点估计值(point estimate)±边际误差(margin of error)。所以我们可以理解边际误差(margin of error)为估算的点估计值与总体参数值之间的大致差异。
第二,置信水平和置信区间的最本质的含义就是:从同一个总体重复抽样(样本量一致),会根据所抽到的样本得到不一样的95%置信区间,但是这些区间中,会有95%的区间抓到(包含)真正的总体参数值。
第三,置信区间是估计总体参数值的,不是估计总体中某一个个体或者某些个体的取值范围,所以碰到这种关于个体类(比如取值范围、个数)的说法一定是错误的。
第四,根据一个随机样本计算出来的特定区间,无法将该区间推广到别的样本上,也就是任何一个样本要想计算置信区间,只能根据抽取到的样本数据进行计算,没有捷径可走。
第五,因为“总体参数值未知但其是一个固定值”的属性,由一个样本计算出来的置信区间,我们永远无法确定该区间是否包含总体参数值。如果参数值落在该区间,那么该区间包含参数值的概率为1,如果参数值未落在该区间,那么该区间包含参数值的概率为0。所以我们可以总结出来一个结论:根据一个样本计算出来的置信区间,其包含真实总体参数值的概率只可能为1或0这两个值。
第六,根据置信水平最本质的含义“从同一个总体重复抽样(样本量一致),会根据所抽到的样本得到不一样的95%置信区间,但是这些区间中,会有95%的区间抓到(包含)真正的总体参数值。”我们可以获知,在重复抽取的多个样本构建的置信区间中,包含参数的区间的占比为95%,但到底是哪个样本构建的区间是包含参数我们永远无法得知。
根据以上六条判别标准,我们可以拿下所有的关于置信水平和置信区间解释的题目。比如,开篇提到的题目:

其中A、B选项里列出的measurements指的是个体的测量值,可以利用第三条判断其是错误选项。
C选项中,区间估计是去估计总体参数的,不是去估计样本统计量的,且12到18是根据一个特定抽取出来的样本计算出来的范围,无法用其来确定别的样本对应的区间范围。
D选项,落于12到18的概率只可能是1或者0,所以这道题选E。我们来分析E选项,如果总体均值是19,那么该样本的区间12到18为不包含19的区间,利用第二条得知,重复抽样构建的多个区间中,不包含参数的区间占比仅为5%,所以是less likely (后者unlikely)to occur。
接下来,我们再看两道典型的真题。

本题答案选B。
A选项,利用判别标准六条中的第四条“根据一个随机样本计算出来的特定区间,无法将该区间推广到别的样本上,也就是任何一个样本要想计算置信区间,只能根据抽取到的样本数据进行计算”。所以我们无法得知别的样本计算的区间范围也是6.73 到7.67。
C和D的典型错误就是95% of the students。E的典型错误也是a student,都可以利用判别标准中的第三条“置信区间是估计总体参数值的,不是估计总体中某一个个体或者某些个体的取值范围,所以碰到这种关于个体类(比如取值范围、个数)的说法一定是错误的。”
正确答案B选项,就是置信水平最本质的含义,也就是判别标准的第二条。

本题答案为A。
A选项就是判别标准的第一条,陈述了margin of error的字面意思。B选项中的majority代表了数据个数,利用判别标准第三条可以排除。C选项的典型错误,可以利用第四条排除,根据一个样本计算的区间无法推广到别的样本计算的区间。D选项可以利用第五条以及第四条进行排除,永远无法得知根据一个样本计算出来的区间估计是否包含真实的总体参数值。E选项也是利用一个样本计算的统计量的值我们无法得知是否等于真实的总体参数值。
相信看到这里,同学们应该明确了,我们常用的置信水平95%的含义。通过这个考点也让我们明白了,这种类型的题目并不是通过大量刷题可以掌握的。
同学们一定要在复习备考过程中,先理解掌握相应的概念考点,在此基础上高效的利用真题,可以达到复习事半功倍的效果!
【竞赛报名/项目咨询+微信:mollywei007】