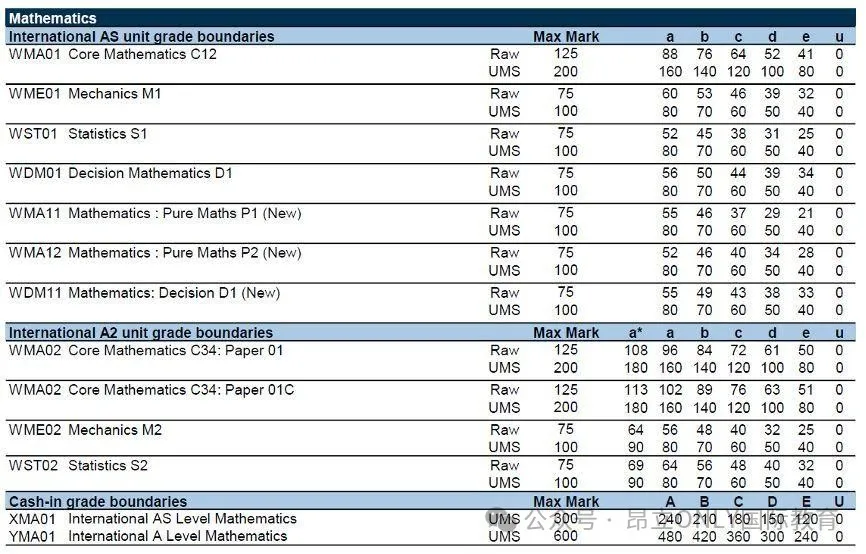
导师简介
如果你想申请英国曼彻斯特大学计算机科学方向的博士,那今天这期文章解析可能对你有用!今天Mason学长为大家详细解析曼彻斯特大学的Prof. Sophia Ananiadou的研究领域和代表文章,同时,我们也推出了新的内容“科研想法&开题立意”,为同学们的科研规划提供一些参考,并且会对如何申请该导师提出实用的建议!方便大家进行套磁!后续我们也将陆续解析其他大学和专业的导师,欢迎大家关注!
Sophia Ananiadou教授是曼彻斯特大学计算机科学学院的教授,同时担任国家文本挖掘中心(NaCTeM)的主任。她在自然语言处理和文本挖掘领域拥有丰富的经验。教授在计算语言学方面获得了博士学位,并曾在希腊雅典大学、法国巴黎第七大学和巴黎索邦大学学习。她的职业生涯经历了日内瓦大学、曼彻斯特城市大学和萨尔福德大学等多个研究机构。
研究领域
教授的研究兴趣集中在自然语言处理领域。她在计算术语学、信息提取、文档分类和聚类、情感检测、摘要、查询扩展以及使用神经符号方法构建资源方面做出了重要贡献。她的研究应用于生物学、医学、环境、法律、健康、人文学科和社会科学等多个领域。
研究分析
《Cluster-Level Contrastive Learning for Emotion Recognition in Conversations》
发表期刊:IEEE Transactions on Affective Computing
研究领域:情感识别、自然语言处理
研究内容:本文提出了一种对话中情感识别的新方法,该方法通过在群集层面上使用对比学习来提高情感识别的准确性。
重要发现:通过对比学习方法能够更准确地识别对话中的情绪,有助于改善人机交互和情感分析。
《Contextualized Medication Event Extraction with Levitated Markers》
发表期刊:Journal of Biomedical Informatics
研究领域:生物医学信息提取、自然语言处理
研究内容:研究聚焦于利用自然语言处理技术从医学文献中提取药物事件信息。
重要发现:提出了一种新颖的方法来提高药物事件信息提取的准确性和效率,对医学研究和临床决策有重要意义。
《Disentangled Variational Autoencoder for Emotion Recognition in Conversations》
发表期刊:IEEE Transactions on Affective Computing
研究领域:情感识别、机器学习
研究内容:本文使用变分自编码器对对话中的情感进行识别和分析。
重要发现:提出的模型能够更有效地理解和识别对话中的复杂情感状态,为人工智能在情感识别方面的应用提供了新的思路。
《Entity Coreference and Co-occurrence Aware Argument Mining from Biomedical Literature》
发表在:Proceedings of the 4th Workshop on Computational Approaches to Discourse (CODI 2023)
研究领域:生物医学文献挖掘、自然语言处理
研究内容:探讨了如何利用实体共指和共现信息来改善从生物医学文献中进行论据挖掘的效果。
重要发现:通过结合实体的共指和共现信息,可以更有效地从复杂的生物医学文献中提取有价值的信息。
这些论文展示了教授在自然语言处理和文本挖掘领域的深入研究和创新贡献。她的研究不仅在学术上有重要意义,而且对于实际应用,如医学信息提取、情感识别等方面有着显著的影响。
项目分析
教授参与的重要项目包括:
- 神经信息提取项目
- Exposome项目,用于健康和职业研究
- 应对新冠疫情的国家核心研究项目
- 与巴基斯坦青少年自残行为相关的心理治疗项目这些项目显示了她在跨学科研究中的影响力和她在应用文本挖掘技术于公共健康问题中的先进作用。
研究想法
跨领域知识集成与自然语言处理
立意:探索如何将自然语言处理技术应用于跨学科知识的集成,例如结合医学、法律和环境科学的数据。
创新点:开发一种新的算法框架,能够理解和处理不同领域的术语和概念,实现跨学科知识的有效整合。
实践意义:有助于解决复杂的社会问题,如公共卫生政策制定、环境变化对健康的影响等。
深度学习在情感分析中的应用
立意:研究深度学习技术在复杂情感状态识别中的应用,特别是在社交媒体文本和在线沟通中。
创新点:利用先进的深度学习模型来识别和分类复杂的情感表达,如讽刺、幽默或混合情感。
实践意义:提高情感分析的准确性和细致度,有助于市场研究、公共意见分析和精神健康监测。
多模态医学数据的文本挖掘
立意:开发一种多模态医学数据处理方法,结合医学图像、临床记录和文献数据,以提高疾病诊断和治疗的效率。
创新点:创建一个集成平台,能够处理和分析文本数据和医学影像,以发现新的疾病标志物和治疗途径。
实践意义:助力精准医疗和个性化治疗策略的发展,改善患者的治疗效果。
自然语言处理在环境监测中的应用
立意:利用自然语言处理技术来分析和预测环境变化,例如通过社交媒体和新闻报道来监测气候变化和环境灾害。
创新点:开发能够从大量文本中提取和分析关于环境问题的关键信息的算法。
实践意义:为环境政策制定提供数据支持,增强对环境问题的公众意识。
申请建议
1. 深入理解导师的研究领域
详细研读教授的论文,特别是近期的发表作品,以理解她在自然语言处理和文本挖掘领域的研究方向。关注她的研究方法和使用的技术,如神经网络、机器学习、数据挖掘等。
2. 准备相关的学术背景和技能
学习和掌握自然语言处理和文本挖掘相关的理论知识。熟练使用编程语言(如Python、Java等)和相关工具(如TensorFlow、PyTorch等)。完成相关的项目或实习,展示你在数据分析、机器学习或自然语言处理方面的实际操作能力。
3. 针对教授的研究方向提出创新想法
基于教授的研究领域,提出自己的研究想法或项目提案。这些想法应具有创新性,并能够展示你的研究能力和对领域的深入理解。考虑如何将你的研究兴趣与教授的研究方向结合起来,以表明你与该研究团队的契合度。
4. 准备完整的申请材料
撰写一份突出你学术背景和研究兴趣的个人陈述,强调你为何适合该研究领域,并具体说明对教授的研究兴趣。同时准备一份详细的RP,说明你打算如何在她的指导下进行研究,包括研究问题、方法论和预期成果。
5. 主动沟通和建立联系
在申请前,可以通过电子邮件与教授联系,简要介绍自己的学术背景和研究兴趣,询问是否有可能加入她的研究团队。在邮件中提出一些具体问题,显示你对她的研究有深入的了解和兴趣。
【竞赛报名/项目咨询+微信:mollywei007】