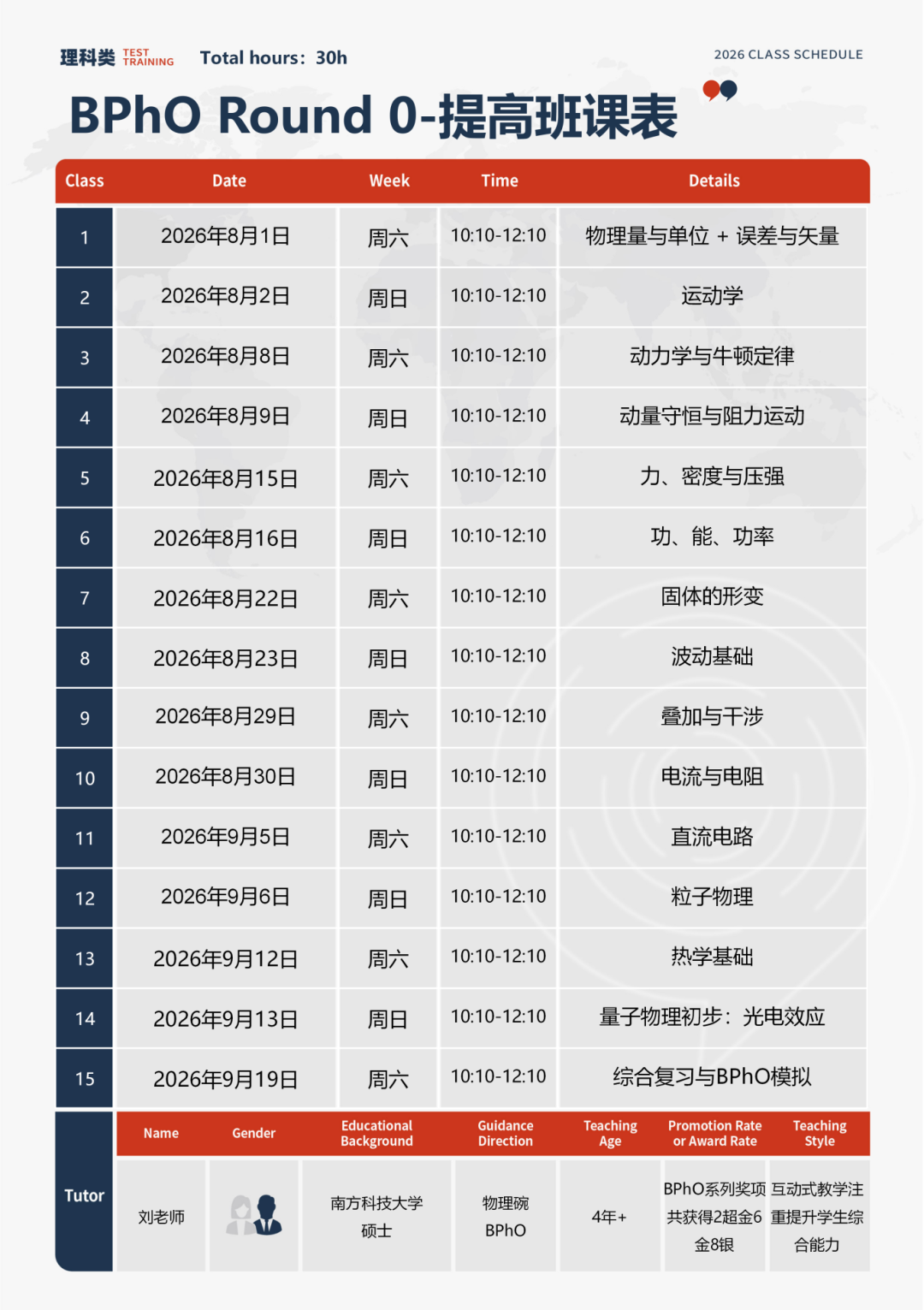
unsetunsetHistGradientBoosting 介绍unsetunset
HistGradientBoosting 是 Scikit-learn 提供的一种高效快速的算法,特别适用于大型数据集(样本量超过 10,000)。
它是一种基于直方图的梯度提升树模型,通过将连续特征值划分为离散的区间(称为“bin”),显著减少需要考虑的分裂点,从而大大加快了计算速度。这使得它相比传统的 GradientBoosting 更加高效。
https://scikit-learn.org/stable/modules/ensemble.html#histogram-based-gradient-boosting
主要特点
- 针对大数据集的高效性:
HistGradientBoostingRegressor优化了大型数据集的处理能力(样本量 ≥ 10,000)。通过使用直方图技术,减少了需要考虑的分裂点数量,提升了模型的计算速度,尤其是在与传统梯度提升方法相比时。 - 原生支持缺失值:该模型能够直接处理数据集中的缺失值(NaN),无需额外的缺失值处理。在训练过程中,模型在每个分裂点决定缺失值样本应该分配到左子节点还是右子节点,依据的是能够带来更大收益的一方。在预测时,模型根据训练时的决策来处理缺失值。
- 基于直方图的分裂方式:模型通过将特征值分箱为固定数量的 bin(默认为 256 个),从而减少了分裂点的复杂性,极大加快了模型的计算效率。
- 借鉴 LightGBM:该算法受到了 LightGBM 的启发,它也是一种通过直方图技术加速训练过程的梯度提升算法。
- 无需缺失值填充器:由于模型原生支持缺失值处理,不需要像其他模型那样在预处理中对缺失值进行额外处理。
主要参数
learning_rate(学习率):每次迭代时更新的步长。较低的学习率可能会提高模型的精度,但会导致训练时间更长。max_iter(最大迭代次数):提升(boosting)迭代的最大次数。max_leaf_nodes(最大叶子节点数):控制每棵树的叶子节点数,影响树的复杂性。min_samples_leaf(最小样本数):形成叶子节点所需的最小样本数。l2_regularization(L2 正则化系数):控制 L2 正则化的强度,以减少过拟合。max_bins(最大分箱数):用于将连续特征离散化的最大分箱数量。early_stopping(早停法):如果模型性能在若干轮迭代后没有改善,可以提前停止训练。
模型优势
- 高效性:适用于传统梯度提升模型计算开销较大的大数据集。
- 处理缺失值:无需在预处理中处理缺失数据,模型原生支持。
- 训练速度快:通过将特征值分箱成直方图,加速了决策树的生成过程。
unsetunset案例1:HGBT vs RFunsetunset
https://scikit-learn.org/stable/auto_examples/ensemble/plot_forest_hist_grad_boosting_comparison.html
在这个示例中,我们比较了随机森林(Random Forest, RF)和直方图梯度提升树(Histogram Gradient Boosting Trees, HGBT)模型在回归数据集上的表现,主要通过得分和计算时间来衡量它们的性能。

通过调整控制树的数量的参数来进行比较:

n_estimators控制随机森林中的树的数量,是一个固定值。max_iter是梯度提升模型中最大迭代次数,对回归和二分类问题来说,迭代次数相当于树的数量。同时,模型实际所需的树的数量取决于停止准则。
HGBT 模型通过梯度提升算法逐步优化模型性能,每棵树都会拟合损失函数关于预测值的负梯度。而随机森林基于集成学习中的“袋装法”(bagging),通过多数投票来预测结果。
HGBT 模型提供了提前停止(early stopping)选项,如果模型在多个迭代中性能不再提高,它会停止添加新树。相比之下,随机森林需要调节树的数量,但通常只需要确保树的数量足够大,进一步增加不会显著提高测试分数即可。
unsetunset案例2:HGBT 特性演示unsetunset
https://scikit-learn.org/stable/auto_examples/ensemble/plot_hgbt_regression.html
Early stopping
设置过高的 max_iter(最大迭代次数)可能会导致预测质量下降,并浪费大量不必要的计算资源。因此,scikit-learn中的HGBT实现提供了自动早停策略。通过该策略,模型会使用一部分训练数据作为内部验证集(由 validation_fraction 参数指定),并在验证集分数在经过 n_iter_no_change 次迭代后没有进一步提升(或变差)时停止训练,允许一定的容差(由 tol 参数控制)。
common_params={"max_iter":1_000,"learning_rate":0.3,"validation_fraction":0.2,"random_state":42,"categorical_features":None,"scoring":"neg_root_mean_squared_error",}hgbt=HistGradientBoostingRegressor(early_stopping=True,**common_params)hgbt.fit(X_train,y_train)Missing values
HGBT模型对缺失值有原生支持。在训练过程中,每次分裂时,树的生成器会根据潜在的增益决定带有缺失值的样本应该去往左子节点还是右子节点。模型会在训练时“学习”出处理缺失值的策略。
Quantile loss
hgbt_quantile=HistGradientBoostingRegressor(loss="quantile",quantile=quantile,**common_params)Monotonic constraints
在某些具有特定领域知识的场景下,可能要求特征与目标变量之间的关系是单调增加或单调减少的。为了满足这一需求,可以在直方图梯度提升树(HGBT)模型中使用单调约束来强制预测的单调性。
如果训练数据包含特征名称,则可以通过传递一个字典来指定这些特征的单调约束。约束的规则如下:
1: 单调增加0: 没有约束-1: 单调减少
monotonic_cst={"date":0,"day":0,"period":0,"nswdemand":1,"nswprice":1,"vicdemand":-1,"vicprice":-1,}hgbt_no_cst=HistGradientBoostingRegressor(categorical_features=None,random_state=42).fit(X,y)