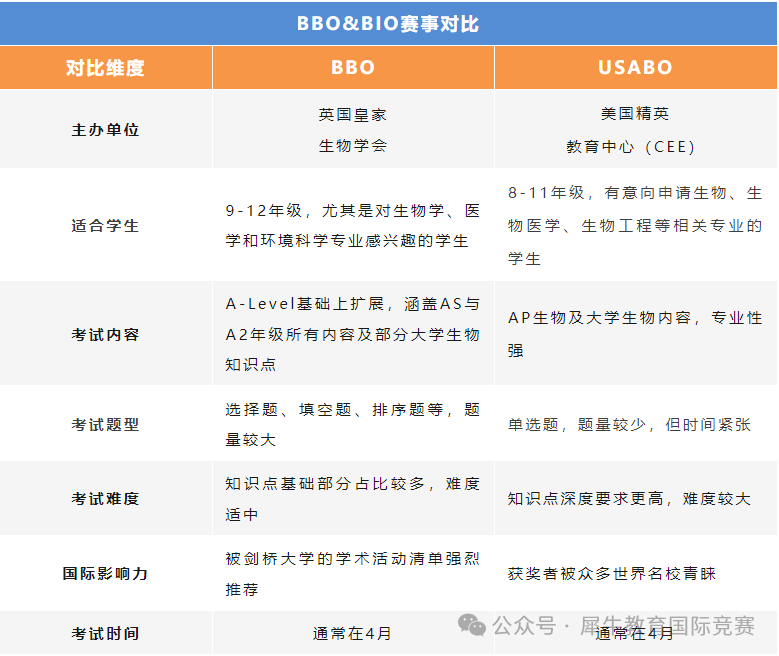
文章目录[隐藏]
文本关键词是指能够表示文本主题内容信息的单词或术语。文本关键词提取是从文本里面把跟这篇文章意义最相关的一些词语抽取出来。
关键词抽取方法
关键词分配
关键词分配:从一个已有的关键词库里面匹配几个词语作为这篇文档的关键词。
第一种方法可以直接使用字符串匹配的思路,尝试使用已知集合进行匹配,这里可以正则匹配的代码。
其次关键词分配也可以考虑使用分类的思路,将每个关键词作为一个类别,使用文本分类的思路将文本转换为类别。
关键词抽取
关键词抽取:根据文本的特征和规则自动地生成一些新的关键词。
关键词抽取是一种抽取类型的过程,它根据文本的特征和规则自动地生成一些关键词。抽取得到的关键词可以来自原始文本,并且不限制是否存在于已知集合。
方法1:IDF关键词抽取
IDF关键词抽取是一种基于统计特征的关键词抽取方法,它是指利用IDF(逆文档频率)来衡量一个词语在文档中的重要程度。
IDF是指一个词语在整个语料库中出现的文档频率的倒数,它反映了一个词语的区分能力。
抽取步骤如下:
- 对文本进行分词,可以使用jieba
- 获取句子每个单词的IDF,和单词频率
- 将单词IDF * 频率进行排序,得到关键词
方法优缺点:
- 优点:思路简单,可控,效率高
- 缺点:需提前计算出IDF,需在大量语料上进行计算;且对未登录词不友好。
方法2:TextRank关键词抽取
TextRank关键词抽取是一种基于图模型的关键词抽取方法,它是由Google的网页排名算法PageRank改编而来的。
PageRank算法是一种通过网页之间的超链接来计算网页重要性的技术,它认为一个网页被其他网页链接的次数越多,说明它越重要。
抽取步骤如下:
- 对文本进行分词,可以使用jieba
- 通过划窗思路对单词构建有向图
- 通过PageRank计算节点重要性
- 通过PageRank值排序得到关键词
方法优缺点:
- 优点:通过图计算重要性,比IDF效果好;可以支持未登录词;
- 缺点:时间复杂度比IDF高,且PageRank需要额外的计算过程;
方法3:Rake关键词抽取
RAKE关键词抽取是一种无监督的关键词抽取算法,其也是借助图的思路来提取关键短语。
抽取步骤如下:
- 对文本进行分词,可以使用jieba
- 通过划窗思路对单词构建有向图
- 计算单词的频率、度数和共现程度
- 按照排序得到关键词
方法优缺点:
- 优点:快速、简单、不需要标注数据,比TextRank快;
- 缺点:比TextRank效果差
方法4:Yake关键词抽取
Yake关键词抽取是一种无监督的关键词提取算法,它可以从单个文档中根据文本统计特征选择最重要的关键词。
Yake的特征提取主要考虑五个因素(去除停用词后):大写term,term频率,term位置,term长度和term相似度。
方法优缺点:
- 优点:效果较好,考虑的因素较多
- 缺点:不支持中文
方法5:KeyBert关键词抽取
KeyBert是一种小型且容易上手使用的关键词提取技术,它利用BERT嵌入来创建与文档最相似的关键词和关键短语。
KeyBert的基本思想是使用BERT提取文档向量和子短语向量,然后用余弦相似度来查找与文档本身最相似的子短语。
方法优缺点:
- 优点:效果较好,支持多语言
- 缺点:复杂度较高
【竞赛报名/项目咨询+微信:mollywei007】