文章目录[隐藏]
距离2023年国赛仅有不到两个月的时间,你准备的怎么样了?
第一次参加国赛,如何从零开始准备?
在团队中担任建模手,应该储备哪些模型?
数学建模的步骤及论文写作,有哪些实用技巧?
今天就跟大家讲讲,国赛备战都需要准备什么?
全国大学生数学建模竞赛是世界上规模最大的数学建模竞赛,一等奖对于想保研或冲奖学金的同学来说都是强有力的加分项,因此每年国赛数模竞赛往往高手如云,竞争激烈!也有很多小伙伴第一次参加国赛不知道怎么入手?今天就跟大家讲下如何在短期内备战国赛。
首先你要清楚你擅长的是那种类型的建模,数模题目是分多种类型的,知道自己的方向再去深度学习做准备,才是最快速有效的方法。
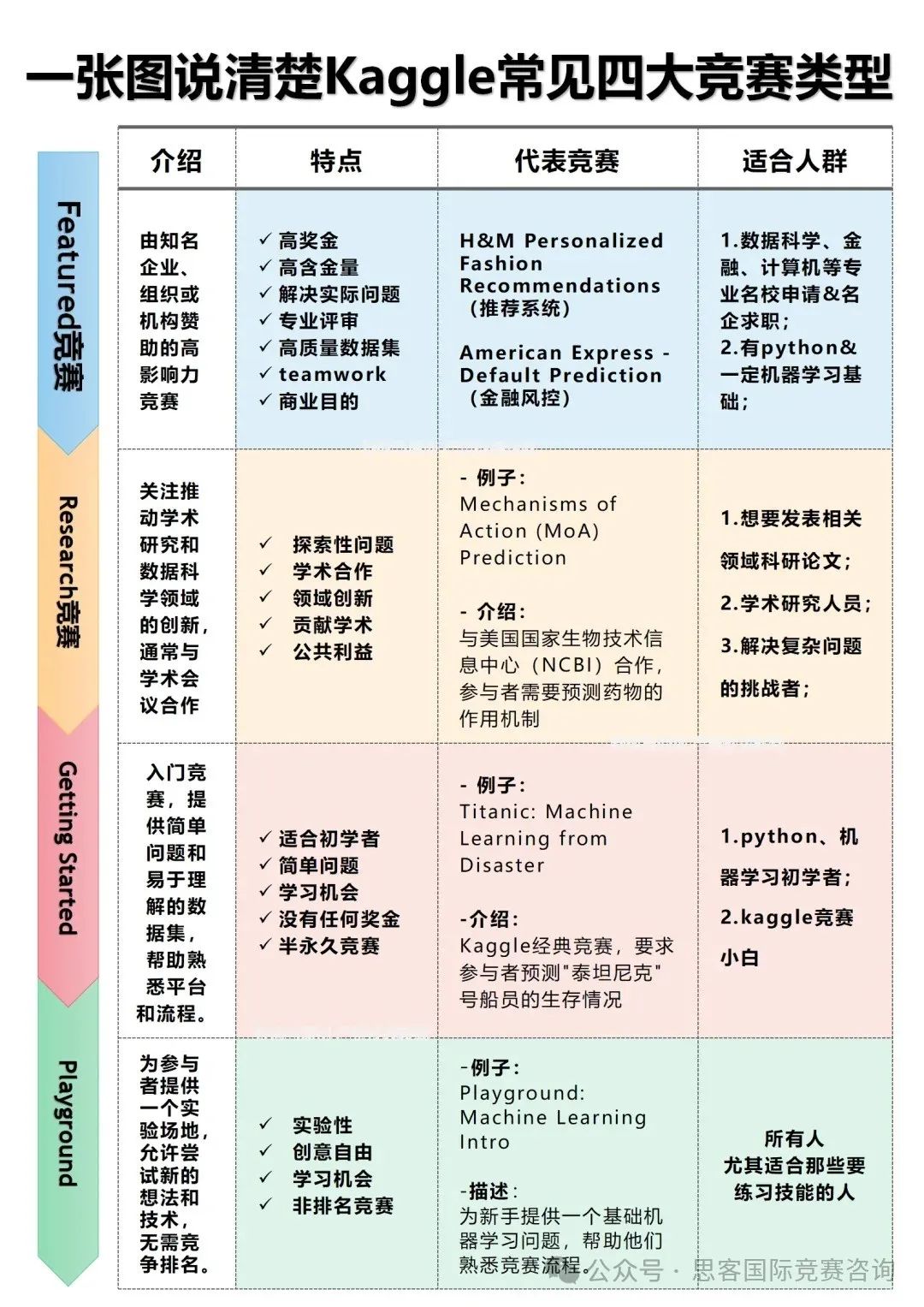
那么目前数模比赛主要分为哪几种呢,如下:

根目前建模类大体分为以上4种,如果是小白建模选手可看往年的比赛论文决定自己感兴趣的题型方向,根据感兴趣方向积累算法模型及数学知识。
预测类及评价类相对容易拿奖、可以提前学习一些常用的分析模板,如:灰色预测、层次分析、时间序列、回归预测等,下面会讲下这几个算法的使用,适合小白入手数模比赛拿奖。
机理加优化类则需要有较强的数学功底,利用数学知识建模再数学求解,这种适合有一定数模经验的人群。
模型储备主要是指参赛队的数学基础,对常见模型、方法的理解,以及灵活运用这些知识的熟练程度。熟练掌握的模型越多,解决问题时的眼界越开阔,可选择的方法也越多。
而对于很多刚入门的小伙伴,去储备整一套数模知识在短期内是不太科学的,那么想要短期上手冲刺奖项,其实只要掌握一些常用的模型就足矣。以下就是比赛种最常用的模型有哪些呢(必收藏!赛前学习必备)

那这些算法都是什么,该怎么用?下面就挑几个算法给大家讲解下教程。
1、层次分析法
层次分析法是一种解决多目标的复杂问题的定性与定量相结合的决策分析方法。该方法将定量分析与定性分析结合起来,用决策者的经验判断各衡量目标之间能否实现的标准之间的相对重要程度。
输入输出描述 输入:根据提示进行指标或者方案两两对比
输出:各方案的量化得分或者同一级的指标权重
案例:通过构建评价指标(景色、费用,居住,饮食、旅途)对候选旅游地(桂林、黄山,北戴河)量化评价,进行选择。(这里层次分析法简化版主要针对评价指标(景色、费用,居住,饮食、旅途)的权重建立分析)
案例操作

step1:选择【层次分析法(AHP简化版)】;(注意:在spsspro计算指标权重时用到的时方根法)
step2:选择判断矩阵阶层(注意:准则层有多少因素,那么判断矩阵阶层就是多少。在本例中,准则层包括景色、费用、居住、饮食、旅途,所以判断矩阵阶层是5)
step3:设置判断矩阵(判断矩阵是对称矩阵),判断矩阵的元素 表示的是第 个因素相对于第 个因素重要性比较结果,比如a21=2,是指费用的重要性会比景色的重要性更大。点击开始分析,即可输出完成的分析报告及结果。
2、TOPSIS(优劣解距离法)
TOPSIS 法是一种常用的组内综合评价方法,能充分利用原始数据的信息,其结果能精确地反映各评价方案之间的差距。基本过程为基于归一化后的原始数据矩阵,采用余弦法找出有限方案中的最优方案和最劣方案,然后分别计算各评价对象与最优方案和最劣方案间的距离,获得各评价对象与最优方案的相对接近程度,以此作为评价优劣的依据。该方法对数据分布及样本含量没有严格限制,数据计算简单易行。
输入输出描述 输入:至少两项或以上的定量变量。
输出:反应考核指标在量化评价中的综合得分
案例:为了客观地评价各风景地点的性价比,根据风景、人文、拥挤程度、票价等因素对各风景地点进行评估。

案例操作

step4:选择【优劣解距离法(TOPSIS)】;
step5:查看对应的数据数据格式,【优劣解距离法(TOPSIS)】要求特征序列为定量变量,分为正向指标变量和负向指标变量,且正向指标变量和负向指标变量的个数之和大于等于两项。
step6:设置变量权重(熵权法、不设置权重)。
step7:点击【开始分析】,完成全部操作。
3、模糊综合评价
模糊综合评价借助模糊数学的一些概念,对实际的综合评价问题提供评价,即模糊综合评价以模糊数学为基础,应用模糊关系合成原理,将一些边界不清、不易定量的因素定量化,进而进行综合性评价的一种方法。
输入输出描述 输入:至少两项或以上的定量变量。
输出:反应考核指标在量化评价中的综合得分。
案例:某饮食行业品牌发布一款新零食,欲了解消费者对该种零食的接受程度。一共有五个评价指标(分别是价格、味道、包装、营养与性价比),以及评语共有四项(分别是很欢迎,欢迎,一般,不欢迎)。

案例操作

step4:选择【模糊综合评价】;
step5:查看对应的数据数据格式,【模糊综合评价】求输入数据为放入 [定量] 自变量X(变量数≥2)。
step6:设置变量权重(熵权法、不设置权重)、模糊算子(主因素决定型、主因素突出型、取小与有界型、加权平均型)。
step7:点击【开始分析】,完成全部操作。
4、灰色关联分析
对于两个系统之间的因素,其随时间或不同对象而变化的关联性大小的量度,称为关联度。在系统发展过程中,若两个因素变化的趋势具有一致性,即同步变化程度较高,即可谓二者关联程度较高;反之,则较低。
因此,灰色关联分析是指对一个系统发展变化态势的定量描述和比较的方法,其基本思想是通过确定参考数据列和若干个比较数据列的几何形状相似程度来判断其联系是否紧密,它反映了曲线间的关联程度。
输入输出描述 输入:特征序列为至少两项或以上的定量变量,母序列(关联对象)为1项定量变量。
输出:反应考核指标与母序列的关联程度。
案例:分析09-18年内,影院数量,观影人数,票价、电影上线数量这些因素对全年电影票房的影响。其中电影票房是母序列,影院数量,观影人数,票价、电影上线数量是特征序列。

案例操作

step4:选择【灰色关联分析】;
step5:查看对应的数据数据格式,【灰色关联分析】要求特征序列为定量变量,且至少有一项;要求母序列为定量变量,且只有一项。
step6:设置量纲处理方式(包括初值化、均值化、无处理)、分辨系数(ρ越小,分辨力越大,一般ρ的取值区间为 ( 0 ,1 ),具体取值可视情况而定。当 ρ ≤ 0.5463时,分辨力最好,通常取 ρ = 0.5 )
step7:点击【开始分析】,完成全部操作。
5、秩和比综合评价
秩和比(RSR)指将效益型指标从小到大排序进行排名、成本型指标从大到小排序进行排名,再计算秩和比,最后统计回归、分档排序。通过秩转换,获得无量纲统计量RSR,以RSR值对评价对象的优劣直接排序或分档排序,从而对评价对象做出综合评价。
输入输出描述 输入:至少两项或以上的定量变量。
输出:反应考核指标在量化评价中的综合得分与分档
案例:对某省10个地区的孕妇保健工作的三个指标进行综合评价

案例操作

step4:选择【秩和比综合评价法】;
step5:查看对应的数据数据格式,【秩和比综合评价法】要求特征序列为定量变量,分为正向指标变量和负向指标变量,且正向指标变量和负向指标变量的个数之和大于等于两项。
step6:设置编秩方式(非整秩方法(推荐使用)、整秩方法、无处理)、分档数量(3档、4档、5档 )、变量权重(熵权法、不设置权重、自定义权重)。
step7:点击【开始分析】,完成全部操作。
6、数据包络分析
数据包络分析是评价多输入指标和多输出指标的较为有效的方法,将多投入与多产出进行比较,得到效率分析,可广泛使用于业绩评价。
输入输出描述 输入:数据包络分析的输入是投入、产出的指标(定量变量)。
输出:效率评估结果,包含具体需要增大或减小哪些投入变量,如何调整产出变量,才能达到最优效率
案例:投入变量为:政府财政收入占 GDP 的比例、环保投资占 GDP 的比例、每千人科技人员数/人。产出变量为:人均 GDP、城市环境质量指数。试分析投入产出效率,得出如何调整投入变量和产出变量,才能达到最优效率。

案例操作

step4:选择【数据包络分析】;
step5:查看对应的数据数据格式,【数据包络分析】要求先放入投入指标(>=1 的定量变量),再放入产出指标(>=1 的定量变量),最后放入索引项(<=1 的定类变量)。
step6:设置 DEA 类型(规模报酬不变(CCR)or 规模报酬可变(BBC)),例子中选择规模报酬可变模型(BBC)。
step7:点击【开始分析】,完成全部操作。
7、时间序列(ARIMA模型)
ARIMA模型的全称叫做自回归移动平均模型,是统计模型中最常见的一种用来进行时间序列预测的模型。
输入输出描述 输入:特征序列为1个时间序列数据定量变量
输出:未来N天的预测值
案例:基于1985-2021年某杂志的销售量,预测某商品的未来五年的销售量。

案例操作

step4:选择【时间序列分析(ARIMA)】;
step5:查看对应的数据数据格式,【时间序列分析(ARIMA)】要求输入1个时间序列数据定量变量。
step6:选择向后预测的期数。
step7:点击【开始分析】,完成全部操作。
8、灰色预测模型GM(1,1)
灰色预测是一种对含有不确定因素的系统进行预测的方法。灰色预测通过鉴别系统因素之间发展趋势的相异程度,即进行关联分析,并对原始数据进行生成处理来寻找系统变动的规律,生成有较强规律性的数据序列,然后建立相应的微分方程模型,从而预测事物未来发展趋势的状况。
输入输出描述 输入:1个时间序列数据定量变量
输出:灰色预测的拟合预测结果
示例:基于某杂志 2006-2021 年某产品的年销售量,使用灰色预测模型对未来三年销售量进行预测。

案例操作

step4:选择【灰色预测模型】;
step5:查看对应的数据数据格式,【灰色预测模型】要求输入1个时间序列数据定量变量。
step6:选择向后预测的期数。
step7:点击【开始分析】,完成全部操作。
9、决策树
决策树中每个内部节点都是一个分裂问题:指定了对实例的某个属性的测试,它将到达该节点的样本按照某个特定的属性进行分割,并且该节点的每一个后继分支对应于该属性的一个可能值。分类决策树叶节点所含样本中,其输出变量的众数就是分类结果。
输入输出描述 输入:自变量 X 为 1 个或 1 个以上的定类或定量变量,因变量 Y 为一个定类变量。
输出:模型输出的决策树结构图及模型的分类效果。
案例:根据红酒的颜色强度,苯酚,类黄酮等变量,生成一个能够区分琴酒,雪莉,贝尔摩德三种品种的红酒的决策树。

案例操作

10、xgboost
xgboost是GBDT的一种高效实现,和GBDT不同,xgboost给损失函数增加了正则化项;且由于有些损失函数是难以计算导数的,xgboost使用损失函数的二阶泰勒展开作为损失函数的拟合。
输入输出描述 输入:自变量X为1个或1个以上的定类或定量变量,因变量Y为一个定类变量。
输出:模型的分类结果和模型分类的评价效果。
案例:根据红酒的颜色强度,脯氨酸,类黄酮等变量,生成一个能够区分琴酒,雪莉,贝尔摩德三种品种的红酒的xgboost。

案例操作

step4:选择【xgboost分类】;
step5:查看对应的数据数据格式,按要求输入【xgboost分类】数据;
step6:进行参数设置(“更多设置”里的参数在客户端可进行设定)
step7:点击【开始分析】,完成全部操作。
【竞赛报名/项目咨询+微信:mollywei007】