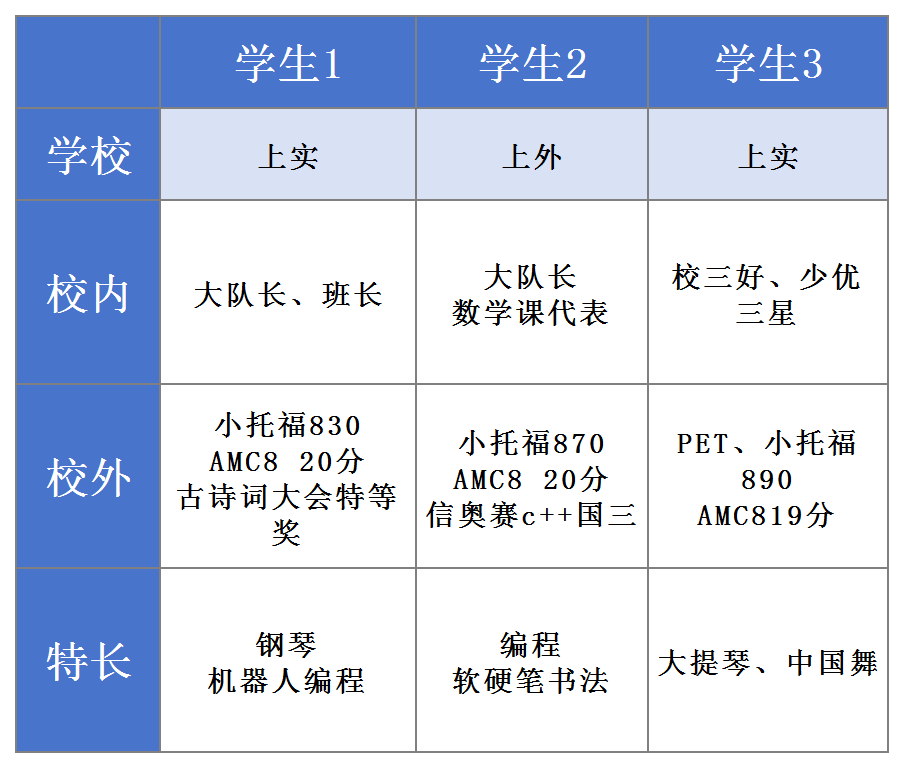
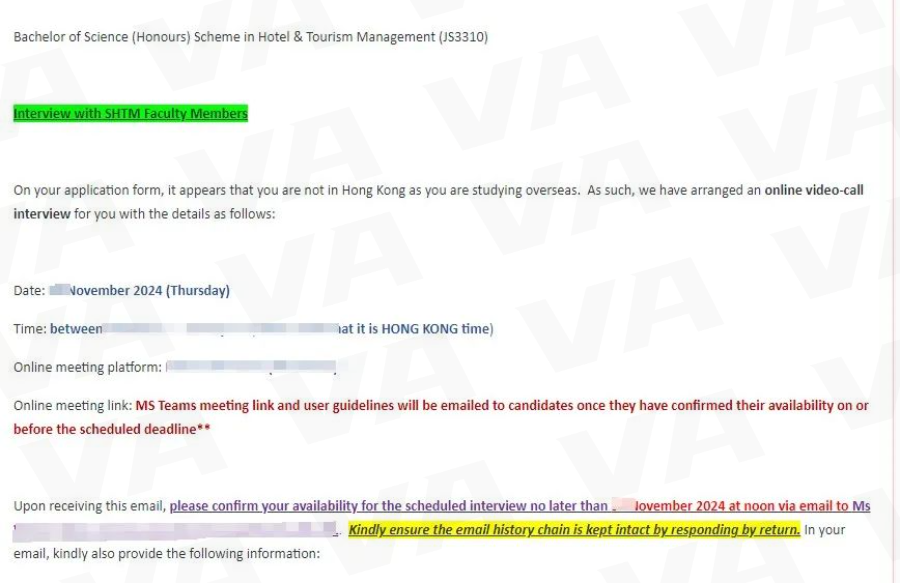
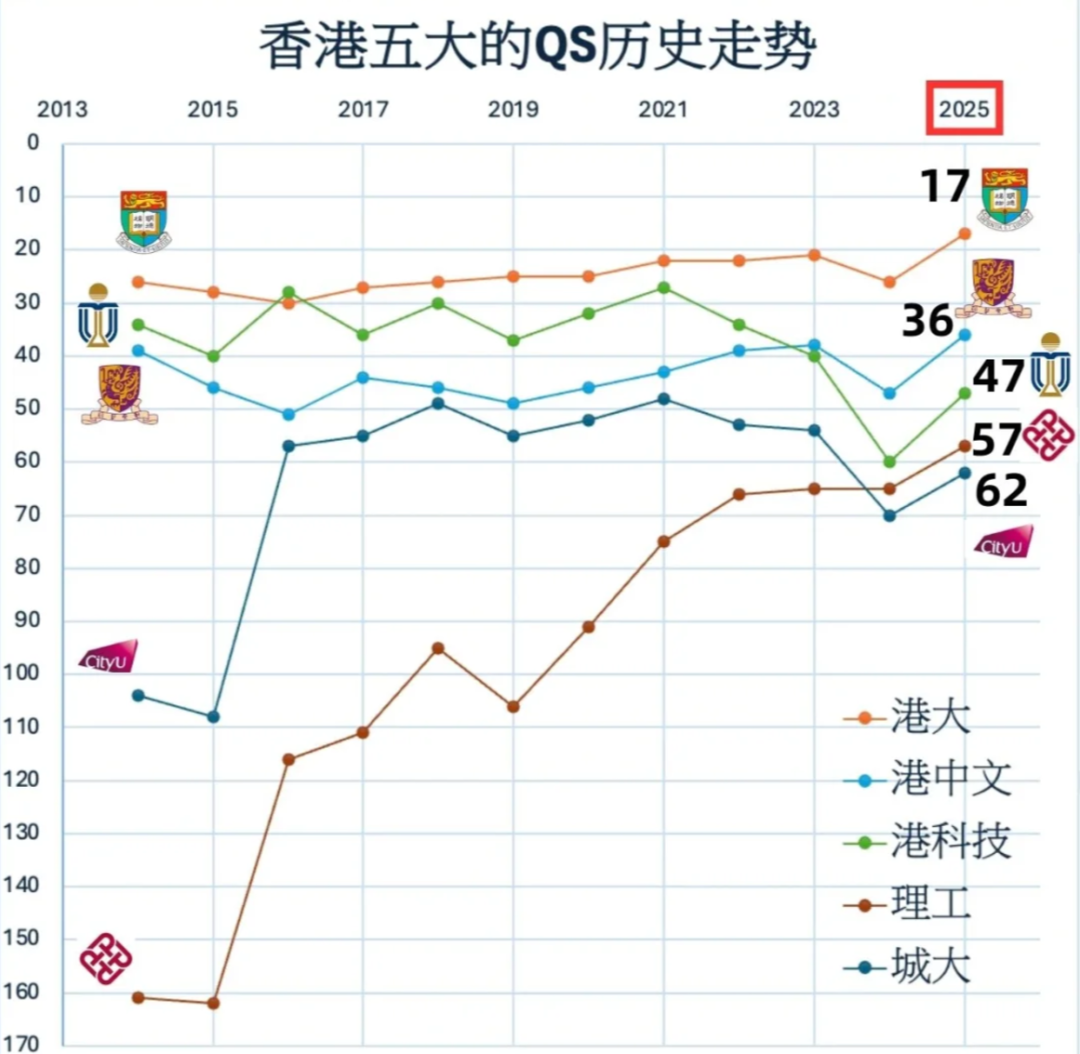
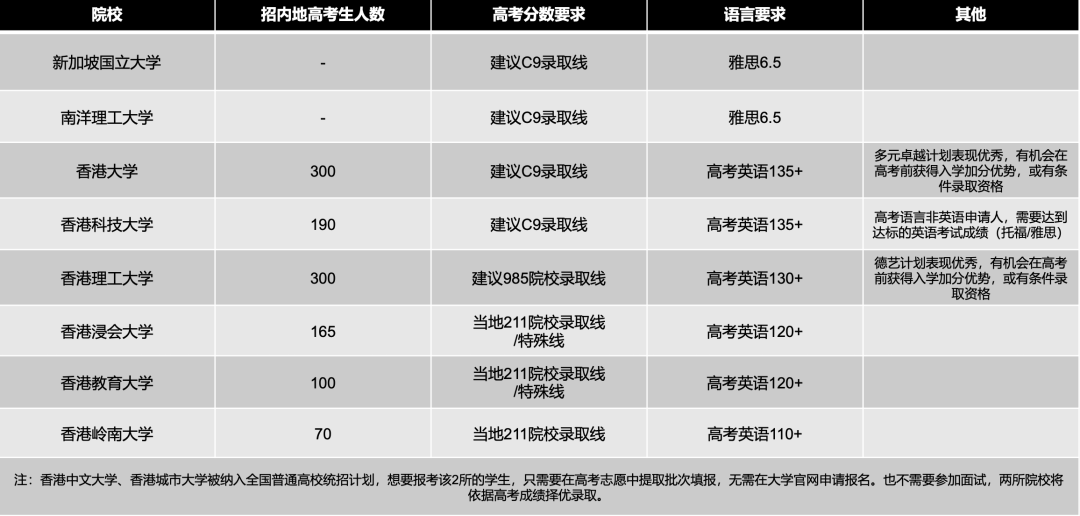
今天我们来看Cambridge Re: think Essay Competition 人工智能领域的选题:Is AI-driven data mining serving us better or is it overriding our privacy?(人工智能驱动的数据挖掘是在更好地为我们服务,还是在侵犯(凌驾于)我们的隐私?)
本题的出题人是 Naama Kanarek 博士(哈佛大学 AP)。
破题点
本题有一个重要破题点,就是 "or" 这个词。
serve OR override? 第一个词暗示人类是主,AI 是客,但第二个词暗示 AI 是主,人类是客。
深一点看,"or" 这个词表明,这个出题者将“AI 数据挖掘会更好地为我们服务”和“AI 数据挖掘会侵犯(凌驾于)我们的隐私”放在了互相对立的位置上。
想回答这些不同深度的问题,选手需要先了解 AI 数据挖掘是如何为我们进行服务的,又是如何会对我们隐私的有威胁。
AI 驱动的数据挖掘如何服务人类?
我们从头说起,从数据挖掘开始说。
数据挖掘其实就像它的名字一样,是在大量的数据中"挖掘"出有价值的信息和知识。就像矿工在矿山挖掘宝藏,数据科学家在数据的海洋里寻找商业和科研的金矿(说句题外话,做职业规划还是优先考虑软件开发而不是数据科学,前者的岗位数大约是后者的 10 倍)。
传统的数据挖掘主要靠统计学和数据库技术,需要人工设计特征、建模。这种做法就像矿工只能用铁锹和镐头,靠经验去挖掘,非常耗时耗力。
相比之下,人工智能驱动的数据挖掘则像是给了矿工一台智能挖掘机。通过机器学习(尤其是深度学习)技术,AI 系统可以自动学习数据中的复杂模式,快速准确地完成特征工程、预测建模等任务,大大提高了挖掘的效率和精度。
这种 AI 驱动的数据挖掘在我们的生活中可以说是无处不在。比如,大家手机中总有那么几个常用的网上购物平台,当你在浏览商品的时候突然发现一个款式很好的衣服,打开一看,网站已经帮你推荐好了尺码,还为你推荐了配套的鞋子和包包 (you may also like...) 。这些“贴心”的服务背后,就是 AI 数据挖掘在默默工作。
你的需求,你的喜好,通通被 AI “挖掘”出来了。虽然这些推荐服务需要耗费平台的开发、运营和算力成本,但作为用户的你不用付一分钱。
不过,免费的服务,便利的服务,是有隐藏代价的,这个代价就是你的隐私。
AI 驱动的数据挖掘如何侵犯我们的隐私?
AI 以一种现在我们已经很熟悉的方式,在服务着我们。它会分析我们的浏览记录、购物记录,结合其他同类人群的行为模式,去了解我们的穿衣风格和身材特点,进而给出个性化推荐。这就像一个懂你的导购员,让我们轻松挑到称心如意的商品。
但是,这也令人细思极恐,我们身处于信息时代,如果 AI 可以轻松地获取我们的喜好,日常行为,个人信息甚至于家庭住址等私密信息,那么掌控着这些数据的 AI 或者组织,是否就会成为我们信息的“掌控者”呢?
AI 驱动的数据挖掘技术可能是价值中立的(现在这点也存疑了),但掌握这些技术的公司可不是价值中立(don't do evil 的说法不一定可信)。
乔治奥威尔的反乌托邦小说《1984》描绘了一个令人不寒而栗的 totalitarian society 。在《1984》的世界里,人们的一举一动都在电屏监视下暴露无遗。看似私密的日记、情书,甚至连思想都可能被"思想警察"侦测和惩罚。
在那个 Orwellian society 里,监控技术本身是价值中立的,但技术背后的老大哥可一点也不价值中立。这就有一点像我们今天生活的数字世界,我们的一言一行都会成为大数据里的一个个点,AI 可以很轻易地根据这些点,描绘出我们的画像 (user persona) 。而这些画像信息的使用者,是一家家有血有肉有自己的商业诉求的公司。
上述这些并不是危言耸听,在本题的出题人是 Naama Kanarek 博士推荐的《无处可藏》中,作者揭露了美国国安局大规模监控公民的丑闻。书里提到的斯诺登的爆料表明,个人信息是如何被美国的国家机器肆意收集和利用的:从美国人的通话记录到网络足迹,从美国人的照片到社交媒体,美国人的一切信息都在政府和科技巨头的眼中一览无余。
最后,让我们回到一开始说的“对立位置”。如果想要有深度地讨论本题,选手可以去探究,关于 AI 驱动的数据挖掘技术,是否真的是“要么负外部性,要么是造福人类”?是否真就只有这两种情况?
剑桥 Re: think 写作竞赛赛题解析系列
1.剑桥Re: think 写作竞赛题目解析(生物科技赛区)
2.剑桥 Re: think 写作竞赛题目解析(哲学和社会学赛区)
【竞赛报名/项目咨询请加微信:mollywei007】