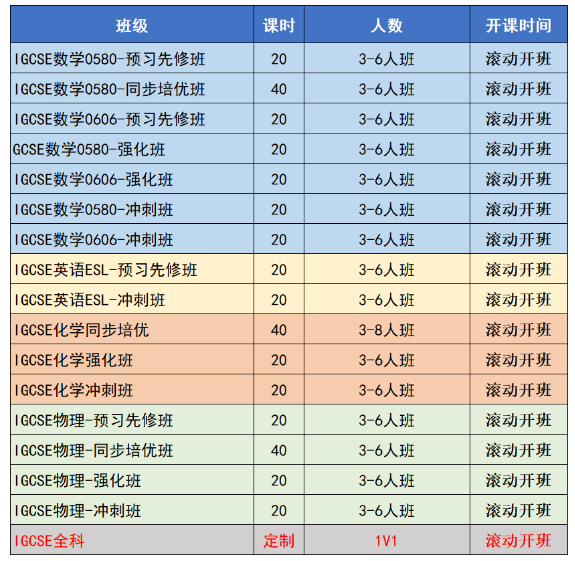
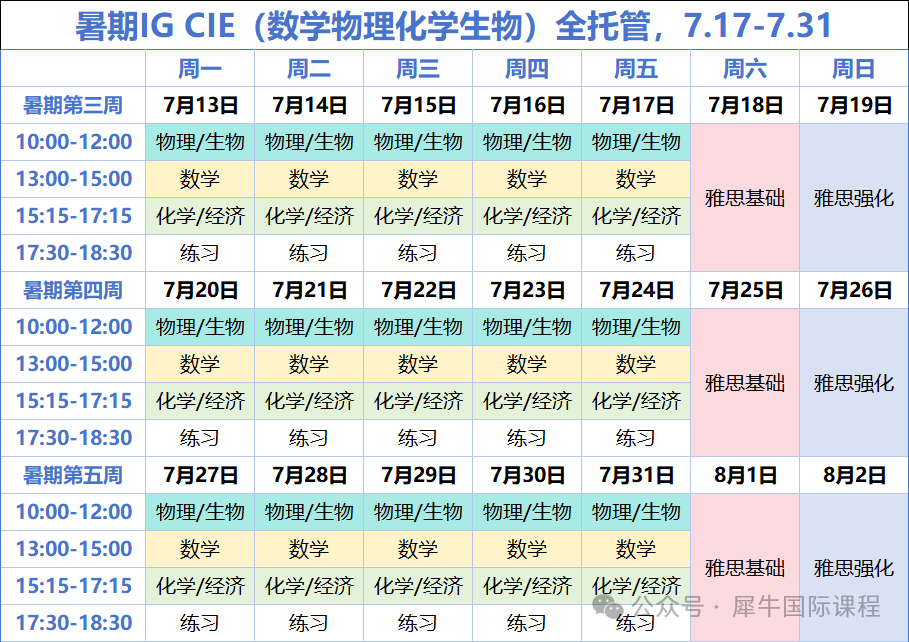
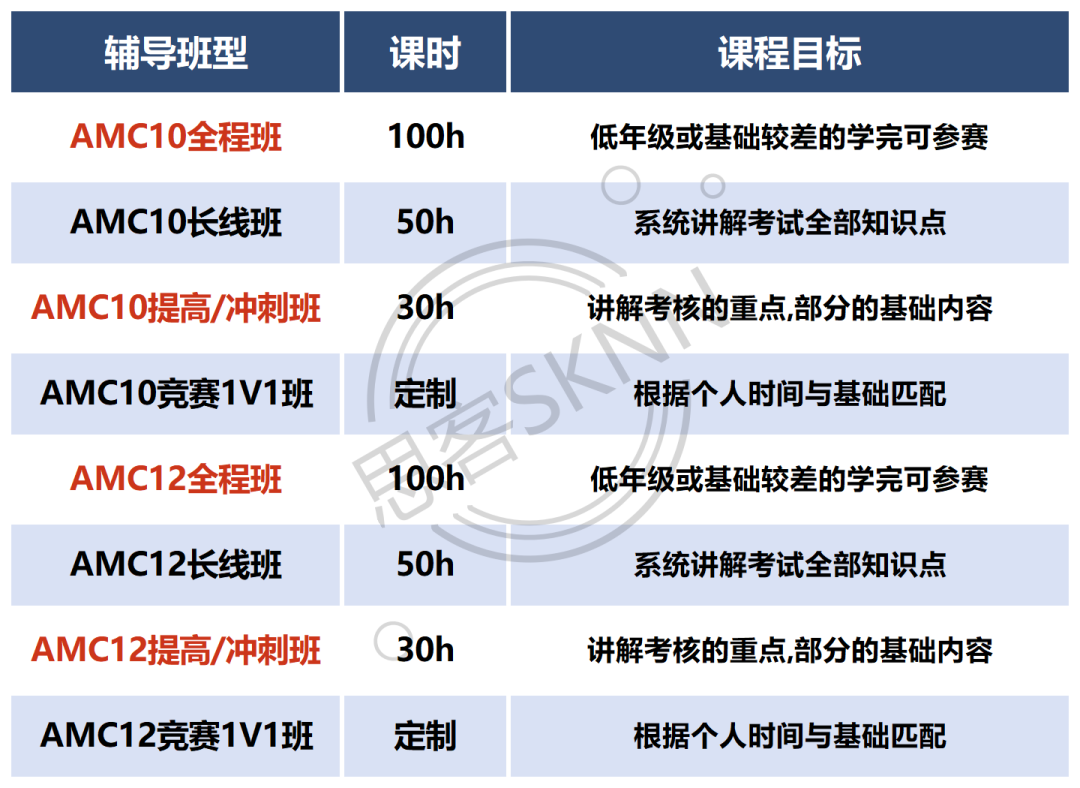
赛题背景
文本到图像模型的流行已经摒弃了一个全新的提示工程领域。一部分是艺术,一部分是悬而未决的科学,机器学习从业者和研究人员正在迅速努力理解提示与其生成的图像之间的关系。
将“4k”添加到提示中是使其更具摄影性的最佳方式吗?提示中的小扰动会导致高度不同的图像吗?提示关键字的顺序如何影响生成的场景?本次比赛的任务是创建一个模型,该模型可以可靠地反转生成给定图像的扩散过程。
赛题任务
本次比赛的目标是扭转生成文本到图像模型的典型方向,不是从文本提示生成图像,而是可以创建一个模型来预测给定生成图像的文本提示。

评价指标
使用预测和实际提示嵌入向量之间的平均余弦相似度得分来评估提交。
优胜方案
第2名
https://www.kaggle.com/competitions/stable-diffusion-image-to-prompts/discussion/410606
我的解决方案和public notebook中基于ViT的方法基本一致。我通过运行 Stable Diffusion 创建了自己的数据集,并训练了一个模型以监督的方式预测句子嵌入。

进行了以下修改以将 fp16 的生成速度提高 4 倍:将调度程序从 DDIM 更改为 DPMSolver++ (diffusers.DPMSolverMultistepScheduler),并将步数从 50 更改为 16。
从Microsoft COCO Captions的字幕用于生成图像。在训练和验证中,从大约 60 万个字幕生成了 50 万张图像。
为了创建更加多样化的提示集,我利用了Open Images Dataset V3 (OID) 和 Image-To-Text 预训练模型中的自然图像。来自 OID 的图像被输入到 Image-To-Text 模型,生成的标题作为提示被输入到 StableDiffusion。OID 包含 9M 自然图像,其中前 5M 用于生成。
最终提交中使用了以下四种模型。
- ConvNeXt xxlarge ( CLIP-convnext_xxlarge-laion2B-s34B-b82K-augreg-rewind )
- BLIP-2 VisionModel (EVA01-g?, Salesforce/blip2-opt-2.7b )
- EVA02-L ( timm/eva02_large_patch14_clip_336.merged2b_s6b_b61k )
- EVA02-e ( timm/eva02_enormous_patch14_plus_clip_224.laion2b_s9b_b144k )
提高分辨率也有显着效果。CLIP 模型通常以 224 的分辨率进行训练,但我认为 224 不利于识别包含多个对象的复杂上下文。
第3名
https://www.kaggle.com/competitions/stable-diffusion-image-to-prompts/discussion/410686
我的方法基于 CLIP 模型,我使用了大约 400K 数据。Diffusion DB 的validation score 与LB score 相关性很好,但仍有0.025 ~ 0.03 的差距。
外部数据集包括:
- Vizwiz image caption ~70k
- Diffusion DB, 300k
- COCO, 25k
- Lexica.art, 10k
微调 CLIP 模型需要格外小心,我们必须尽可能保持原始 CLIP 权重以获得最佳性能。我发现以下两种方法总共将分数提高了 ~ +0.02,并且花了很多时间来寻找最佳超参数。
- LP-FT(线性探头然后微调)
- EMA 和逐层学习率衰减的结合
数据集增强:
- Crop/RandomErase/RandAug(无色调分离、曝光和均衡)
- 相同的提示和不同的种子
- 隐形水印增强
第4名
https://www.kaggle.com/competitions/stable-diffusion-image-to-prompts/discussion/410798
文本检索使用预训练的CLIP-bigG从 56M 预计算文本嵌入中进行 top-k 详尽搜索,然后使用预训练的CLIP-H14进行余弦相似度过滤。
CLIP从 160 万个“提示组件”的集合中预计算的 CLIP-bigG 文本嵌入。使用预先计算的文本嵌入并将提示组件合并到提示中的 Top-k 检索。
Prompt数据集来源:
- Caption Set (Text Retrieval + Image Generation)
- WIT (Text Retrieval + Image Generation)
- Generated Prompts (Text Retrieval + Image Generation)
- YFCC 100M open subset (Text Retrieval only)
- Laion CoCo (Text Retrieval only)
- Datacomp Small (Text Retrieval only)
- Prompt Components (Interrogator only)
第5名
我们的方法涉及训练多个图像模型以直接从图像预测提示嵌入(由句子转换器生成),然后集成这些模型的预测。最终提交的是四个模型的集合:
- eva02_large
- convnext_xxlarge
- convnext_large
- vit_large
| dataset name | # of prompts | images per prompt | Total images |
|---|---|---|---|
| cc3m | 249,593 | 3 | 748,781 |
| lexica | 67,101 | 3 | 201,303 |
| diffusiondb | 326,035 | 3 | 978,105 |
| cc3m part2 | 1,166,852 | 1 | 1,166,852 |
| diffusiondb part2 | 1,371,480 | 1 | 1,371,480 |
| mscoco | 197,527 | 3 | 592,583 |
| Total: | 3,378,588 | 1or3 | 5,059,104 |
第6名
https://www.kaggle.com/competitions/stable-diffusion-image-to-prompts/discussion/410768
从图像/视频字幕数据集的字幕创建 8.87M SD2 生成的图像,并在对数据集进行去重/预处理之后,使用 timm 最新的主干(即 eva、convnext、swin)训练生成的图像。
对于训练数据集,丰富的词汇和适度的文本字幕长度对我来说很重要,所以我根据这两个因素选择了数据集。
第7名
https://www.kaggle.com/competitions/stable-diffusion-image-to-prompts/discussion/410618
我们假设训练数据将在本次比赛中发挥重要作用,因此我们开始尽快使用 Stable Diffusion 生成自定义图像。我们试图收集一组不同的提示,通常使用竞争指标将它们的余弦相似度限制为小于 0.7。我们从以下来源过滤了我们认为质量最高、相关性低的提示:
- Diffusion DB
- Conceptual Captions
- COCO image captions
- Flickr Image Captions
- The ChatGPT prompts
我敢肯定,我们大多数人一开始都在努力寻找一个好的验证集。我们发现确保我们的验证提示来自各种来源并且与我们的训练数据具有低相关性非常重要。
由于我们使用的是 CLIP 模型,可以初始化模型的投影头,将 CLIP 主干输出映射到竞赛使用的 384 嵌入。我们使用自定义提示生成器生成一百万个随机提示,并使用 CLIP 模型的文本塔创建它们的文本嵌入,并使用比赛模型all-MiniLM-L6-v2进行嵌入。